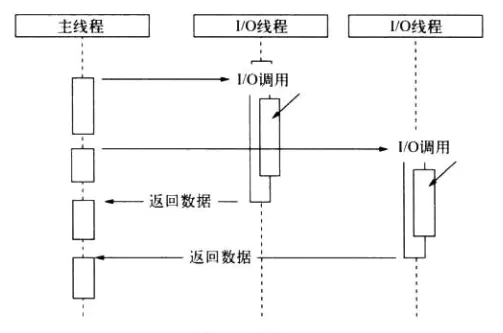
一,异步IO nodejs是一种单线程的语言,单线程并不是说nodejs进程中真的只包含一个线程,而是nodejs只有一个主线程用于处理业务逻辑。余下的线程是为支持nodejs的异步io功能,被叫做io线程,io线程主要用于接收主线程的io事件请求,然后发起io调用,并将io调用的结果传递到主线程。如下图所示(图片来自于《深入浅出Node.js》):
nodejs中进行异步io调用通常类似于:
1 2 3 4 function callback (err, data ){} obj.ioMethod (arg, callback);
例如异步读取文件的代码示例如下所示:
1 2 3 4 5 6 7 8 9 var fs = require ("fs" );fs.readFile ("a.txt" , function (err, data ){ if (err){ console .log (err); } else { console .log (data); } })
从上面异步io的流程中可以看出, readFile方法完成(返回)时,数据并没有真正读回来,等io线程完成文件读取之后,主线程检测到此事件之后,才会执行callback处理读取回来的数据(此处只是直接输出到console)。由此可知,readFile和callback虽然同样是主线程执行的,但其实并没有多大的关联,也就是说,我们无法从主线程的执行顺序来判定这两个操作是否是同一个调用链。所以当callback抛出异常时,我们其实得不到一个完整的调用栈。或者,我们需要追踪一个调用链,并且分别统计每个调用环节的耗时,因为异步io的原因,就无法完成了。
当然,有此需求,就会有人想办法解决,下面就介绍一些可行的方案。
二. AsyncListener + Continuation-Local Storage
AsyncListener 提供了在异步调用时添加listener功能的机制,并且,AsyncListener能保证调用链的完整。Continuation-Local Storage (简称CLS),在AsyncListener的基础上,提供了更宜于使用的api。
三. async_hooks模块 nodejs从v8.0开始,原生提供了类似于AsyncListener的功能,官方API文档 。async_hooks,模块提供了一个用于注册回调函数的 API,这些回调函数可追踪在 Node.js 应用中创建的异步资源的生命周期。
async_hooks提供了有限的几个api,createHook , enable , disable , executionAsyncId , triggerAsyncId , 这几个api即可为调用链的追踪提供可能。其中的enable和disable非常容易理解,即开启或者停止此功能。createHook比较复杂,在理解了此方法之后,executionAsyncId和triggerAsyncId就很好理解了。createHook方法定义如下:
async_hooks.createHook(callbacks)
Added in: v8.1.0
callbacks <Object> the callbacks to register
Returns: {AsyncHook} instance used for disabling and enabling hooks
createHook方法主要用于注册一系列回调函数,这些回调函数会在异步操作的各个生命周期的事件中被调用。回调函数包含4个,init()/before()/after()/destroy() ,当然视业务不同,有时候并不需要提供完整的4个回调函数。
在开始说明这些回调函数的作用之前,先说明一件事件,我们可能试图在回调函数中调用console.log来打印出一些信息,但是console.log本身就是一个异步操作, 这会导致另一个异步事件的产生,而另一个异步事件又会试图调用console.log打印信息,所以会得到一个死循环。为了解决这个问题,官方给出了方法,可以使用fs的writeSync方法来输出打印数据,例如:
1 fs.writeSync (1 , `${type} (${asyncId} ): trigger: ${triggerAsyncId} execution: ${eid} \n` );
下面我们依次来看几个回调函数的定义,以及参数的含义:
1.init(asyncId, type, triggerAsyncId, resource)
asyncId <number> 异步资源的唯一IDtype <string> 异步资源的类型,这是nodejs内部定义好的,当然也提供了自定义的方案triggerAsyncId <number> 创建此异步资源的执行上下文的唯一ID,即此资源调用链上的父IDresource <Object> reference to the resource representing the async operation, needs to be released during destroy
当一个可能触发异步事件的类初始化的时候,init方法将会被调用。然而随后的before()/after()/destroy()并不是一会被调用。每个异步资源,会被分配一个唯一的id,即: asyncId。 type : 一个表示引发init被调用的异步资源的类型,目前内置了部分,也可以自定义,详见官方api文档。triggerAsyncId : 表示创建引发init回调的异步资源的异步资源id,可以理解为目前异步资源的父id。resource : 一个代表异步资源的对象,可以从此对象中获得一些异步资源相关的数据。比如: GETADDRINFOREQWRAP 类型的异步资源对象,提供了hostname。
2.before(asyncId)
当一个异步操作初始化(例如 TCP服务端接收到一个新的连接)或者完成时(例如写数据到磁盘)其对应的回调函数将被调用。before回调将会在异步操作的回调执行之前被调用。asyncId表示执行回调函数的异步资源的唯一ID。理论上异步资源的回调将会被执行0或者多次,因此before回调也可能被执行0到多次。
3.after(asyncId)
after回调,会在异步资源的回调被执行之后立即调用。
4.destroy(asyncId)
当asyncId代表的资源被销毁的时候,destrory回调被调用。或者当通过内置的api emitDestroy()进行异步调用时。
了解了async_hooks模块中的主要方法,以及方法的参数之后,我们以读取文件为例,将其中的调用链显示出来如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 'use strict' ;const async_hooks = require ('async_hooks' );const fs = require ('fs' );let indent = 0 ;async_hooks.createHook ({ init (asyncId, type, triggerAsyncId ) { const eid = async_hooks.executionAsyncId (); const indentStr = ' ' .repeat (indent); fs.writeSync ( 1 , `${indentStr} ${type} (${asyncId} ):` + ` trigger: ${triggerAsyncId} execution: ${eid} \n` ); }, before (asyncId ) { const indentStr = ' ' .repeat (indent); fs.writeSync (1 , `${indentStr} before: ${asyncId} \n` ); indent += 2 ; }, after (asyncId ) { indent -= 2 ; const indentStr = ' ' .repeat (indent); fs.writeSync (1 , `${indentStr} after: ${asyncId} \n` ); }, destroy (asyncId ) { const indentStr = ' ' .repeat (indent); fs.writeSync (1 , `${indentStr} destroy: ${asyncId} \n` ); }, }).enable (); fs.readFile ("a.txt" , 'utf8' , function (err, data ){ }); fs.readFile ("b.txt" , 'utf8' , function (err, data ){ });
上面的代码,并行读取a.txt和b.txt,从nodejs的异步特性来看,a.txt和b.txt应该是两个不同的调用链,运行上面代码,输出的结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 peachcat@peachcat:~/nodejs $ node async_hooks.js FSREQWRAP(2): trigger: 1 execution: 1 FSREQWRAP(3): trigger: 1 execution: 1 before: 2 FSREQWRAP(4): trigger: 2 execution: 2 after: 2 before: 3 FSREQWRAP(5): trigger: 3 execution: 3 after: 3 destroy: 2 destroy: 3 before: 4 FSREQWRAP(6): trigger: 4 execution: 4 after: 4 before: 5 FSREQWRAP(7): trigger: 5 execution: 5 after: 5 destroy: 4 destroy: 5 before: 6 FSREQWRAP(8): trigger: 6 execution: 6 after: 6 before: 7 FSREQWRAP(9): trigger: 7 execution: 7 after: 7 destroy: 6 destroy: 7 before: 8 after: 8 before: 9 after: 9 destroy: 8 destroy: 9
从输出结果,可以看出,a.txt的调用链路为: 1 -> 2 -> 4 -> 6 -> 8 ,而b.txt的调用链路为: 1 -> 3 -> 5 -> 7 -> 9,可以看出,根结构是一样的,从第二个操作开始,就是各自不同的链路了。我们将a和b的操作,修改为在a.txt的回调中去读取文件b.txt,相应的修改代码为:
1 2 3 4 fs.readFile ("a.txt" , 'utf8' , function (err, data ){ fs.readFile ("b.txt" , 'utf8' , function (err, data ){ }); });
调用输出结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 FSREQWRAP(2): trigger: 1 execution: 1 before: 2 FSREQWRAP(3): trigger: 2 execution: 2 after: 2 destroy: 2 before: 3 FSREQWRAP(4): trigger: 3 execution: 3 after: 3 destroy: 3 before: 4 FSREQWRAP(5): trigger: 4 execution: 4 after: 4 destroy: 4 before: 5 FSREQWRAP(6): trigger: 5 execution: 5 after: 5 destroy: 5 before: 6 FSREQWRAP(7): trigger: 6 execution: 6 after: 6 destroy: 6 before: 7 FSREQWRAP(8): trigger: 7 execution: 7 after: 7 destroy: 7 before: 8 FSREQWRAP(9): trigger: 8 execution: 8 after: 8 destroy: 8 before: 9 after: 9 destroy: 9
由上面输出可以得知,此次调用的链路为 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7 ->
四,async_hooks的应用 async_hooks提供的这些功能,可以扩展出一些非常实用的应用场景。比如可以将原来由于异步回调,导致异常错误栈无法显示完全,可以使用async_hooks功能进行修复。更进一步,我们可以使用async_hooks完成类似于java中的ThreadLocal的功能。现在已经有现成的npm包使用async_hooks,提供了在调用上下文中保存一些数据的功能。比如:asyncctx ,其核心代码非常少,我们来分析一下实现原理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 class ContinuationLocalStorage { constructor ( this .initMap (); this .hookFuncs = { init : (id, type, triggerId ) => { const oriTriggerId = triggerId; if (triggerId == null ) { triggerId = this ._currId ; } let triggerHook = this .idHookMap .get (triggerId); if (!triggerHook) { triggerId = ROOT_ID ; triggerHook = this .idHookMap .get (triggerId); } else { while (triggerHook.type === 'PROMISE' && !triggerHook.activated && this .idHookMap .has (triggerHook.triggerId )) { triggerId = triggerHook.triggerId ; triggerHook = this .idHookMap .get (triggerId); } } this .idHookMap .set (id, { id, type, triggerId, oriTriggerId, triggerHook, activated : false }); }, before : (id ) => { this ._currId = id; let hi = this .idHookMap .get (id); if (hi) { if (!hi.activated ) { hi.data = hi.triggerHook ? hi.triggerHook .data : undefined ; } hi.activated = true ; } else { this ._currId = ROOT_ID ; } }, after : (id ) => { if (id === this ._currId ) { this ._currId = ROOT_ID ; } }, destroy : (id ) => { if (this .idHookMap .has (id)) { if (id === this ._currId ) { nodeproc._rawDebug (`asyncctx: destroy hook called for current context (id: ${this .currId} )!` ); } this .idHookMap .delete (id); } } }; this .hookInstance = asyncHooks.createHook (this .hookFuncs ); this .enable (); } get currId () { return this ._currId ; } getContext ( let hi = this .idHookMap .get (this .currId ); return hi ? hi.data : undefined ; } setContext (value ) { let hi = this .idHookMap .get (this .currId ); if (!hi) { throw new Error ('setContext must be called in an async context!' ); } hi.data = value; return value; } getRootContext ( let hi = this .idHookMap .get (ROOT_ID ); if (!hi) { throw new Error ('internal error: root node not found (1)!' ); } return hi ? hi.data : undefined ; } setRootContext (value ) { let hi = this .idHookMap .get (ROOT_ID ); if (!hi) { throw new Error ('internal error: root node not found (2)!' ); } hi.data = value; return value; } initMap (value ) { this .idHookMap = new Map (); this .idHookMap .set (ROOT_ID , { id : ROOT_ID , type : 'C++' , triggerId : 0 , activated : true }); this ._currId = ROOT_ID ; if (value) { this .setRootContext (value); } } }
上面的代码,使用了一个Map来保存每个调用链的上下文数据,由initMap方法进行初始化,并且生成ROOT_ID(值为1),保存在Map中的数据,以当前操作的id为key,值为一个对象,其中triggerId表示其父操作的id,由此,可以在Map中记录一个树形结构的上下文链。
五,使用asyncctx,完成一个调用链时间统计功能 通过上面的async_hooks原理和扩展的npm包的说明,我们已经可以考虑使用async_hooks功能,来完成一些实际的事情的。下面我们使用asyncctx来完成一个统计调用链中,统计各个异步资源耗时的功能。
1.首先,我们需要定义一个数据结构,用于保存调用链中各节点的耗时和节点的父子关系,以及调用的开始和结束时间,为此我们定义一个Span类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 'use strict' ;const {ContinuationLocalStorage } = require ('asyncctx' );const fs = require ('fs' );const cls = new ContinuationLocalStorage ();class Span { constructor (operationName, parent ) { this .operationName = operationName; this .parent = parent; this .start = (new Date ()).getTime (); this .end = 0 ; } finish ( if (this .parent ){ this .parent .finish (); } this .end = (new Date ()).getTime (); } toString ( let str = `Operation: ${this .operationName} , ${this .end - this .start} ms` ; if (this .parent ){ str += `, Parent: ${this .parent.operationName} \n` ; str += this .parent .toString (); } return str; } }
Span的构造方法中,需要传递一个操作名称,以及其父节点,我们可以想像到,父节点的获取需要使用asyncctx来完成,因为操作之间是异步的,我们必须要使用asynccxt来传递父子关系。初始化Span对象时,记录当前的时间。其中的finish方法,用于设置结束时间,并且同时结束父节点的耗时统计(我们演示的例子,为单一嵌套的,若有并行请求的时候,此做法是不可行的)。toString()方法用于输出节点统计的耗时,以及父节点的信息。
我们打算继续使用fs.readFile来做为演示的例子,为了更接近于真实的使用场景,我们对fs.readFile做一下改造。
2.改造fs.readFile
1 2 3 4 5 6 7 8 9 10 11 let originReadFile = fs.readFile ;fs.readFile = function (file, callback ){ let ctx = cls.getContext (); let span = new Span (`Read ${file} ` , ctx); cls.setContext (span); originReadFile (file, function (err, data ){ callback (err, data); span.finish (); }); }
为了使用fs.readFile时,无代码入侵,我们重写了readFile方法,在调用原始方法之前,开启统计,调用结束之后,结束统计。由代码中可知,span的父节点是直接通过ctx.getContext()获取的。
3.调用代码
1 2 3 4 5 6 7 8 9 10 11 let rootSpan = new Span ('root' , null ); cls.setRootContext (rootSpan); fs.readFile ("a.txt" , function (err, data ){ fs.readFile ("b.txt" , function (err, data ){ let span = cls.getContext (); span.finish (); console .log (span.toString ()); }); });
运行代码,输出的结果如下:
1 2 3 4 peachcat@peachcat:~/nodejs $ node async.js Operation: Read b.txt, 1ms, Parent: Read a.txt Operation: Read a.txt, 2ms, Parent: root Operation: root, 2ms
由上面输出结果可以看出来,同我们预想的一样,root -> a.txt ->
六,参考文档